Un grave fallo de AWS afecta a millones de usuarios de Canva, Roblox, Snapchat y más

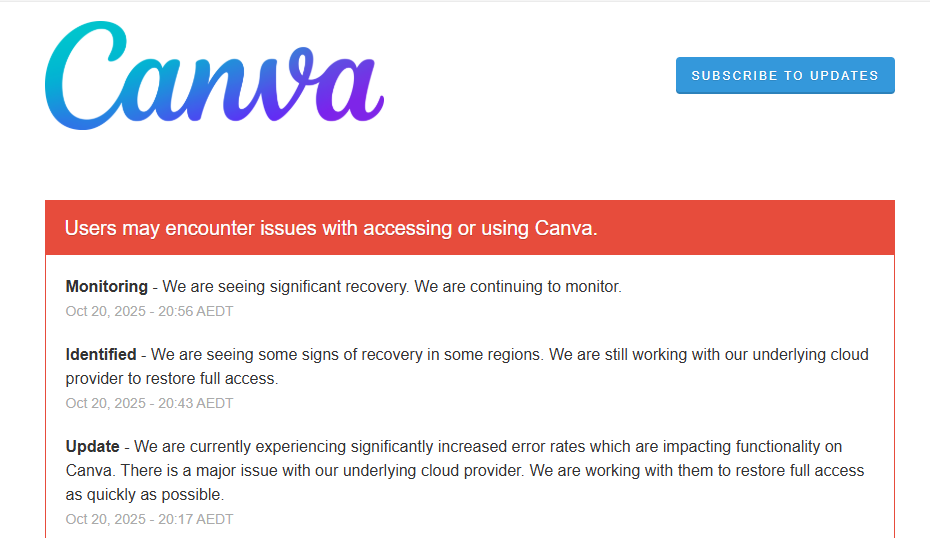
Un fallo de Amazon Web Services ha provocado fallos en decenas de servicios y plataformas utilizadas en todo el mundo, incluyendo desde juegos como Fortnite y Roblox, así como Snapchat, Duolingo, hasta herramientas como Canva y Perplexity.
Esto evidencia que no solo los ciberataques pueden afectar a plataformas con millones de usuarios. El fallo de AWS representa un nuevo episodio de fragilidad digital global que recuerda al mundo hasta qué punto la vida contemporánea depende de una infraestructura invisible, y lo que ocurre cuando un punto neurálgico de esa red sufre un espasmo.
La verdadera magnitud de este problema que afecta a este servicio no se midió por los dispositivos de Amazon que han dejado de funcionar durante el fallo, sino por el ecosistema diverso de servicios que se vinieron abajo con él. No se trataba solo de que Alexa dejara de responder o de que Prime Video interrumpiera una película. El fenómeno demostró ser un perfecto ejemplo del efecto dominó en la era digital.
Plataformas aparentemente sin ninguna conexión entre ellas como Duolingo, donde millones practican idiomas; Canva, herramienta esencial para diseñadores y emprendedores; el buscador de IA Perplexity; la red social Snapchat; y gigantes del ocio como Fortnite y Roblox, compartían un denominador común invisible: su dependencia —aunque sea parcial— de los servidores de AWS.
Incluso servicios financieros como Venmo y operaciones de pago en otras plataformas se vieron comprometidos, añadiendo un matiz de inquietud económica al problema.
La paradoja de la nube: eficiencia y vulnerabilidad
Amazon Web Services es el mayor proveedor de infraestructura en la nube del mundo. Su modelo de negocio es brillante y eficiente: ofrece a empresas de todos los tamaños un acceso flexible y escalable a una potencia de computación que de otra manera tendrían que construir y mantener por sí mismas.
Esta centralización de recursos es lo que permite a una startup escalar a nivel global en cuestión de días y a una empresa consolidada optimizar sus costos.
Sin embargo, este lunes se puso de manifiesto la otra cara de la moneda. La concentración de tanto poder digital en unos pocos puntos de fallo crea una vulnerabilidad sistémica.
La eficiencia tiene un precio: la interdependencia. Cuando un servicio clave en una región crítica de AWS falla, medio internet tiene problemas. La caída no fue una desconexión general de la red, sino más bien un bloqueo en una arteria principal del flujo de datos global, afectando a todos los órganos que dependían de ella.
De acuerdo con la información oficial, el epicentro del problema se situó en la región US-EAST-1, un complejo de centros de datos de Amazon Web Services (AWS) en el norte de Virginia, Estados Unidos.
A partir de las 08:40 hora peninsular española, lo que comenzó como un «aumento en las tasas de error y latencias» en los paneles de control de los ingenieros de Amazon, se transformó rápidamente en una ola de frustración para millones de usuarios en todo el planeta. El corazón de la nube, ese concepto etéreo, tenía un problema muy físico y localizado.
El incidente, que al momento de escribir estas líneas continúa afectando a algunos servicios, sirve como una lección para las empresas. Para los desarrolladores y arquitectos de sistemas, es un recordatorio de la crítica importancia de diseñar infraestructuras multi-región y con planes de contingencia robustos para la recuperación ante desastres.
Para el usuario común, el evento fue una incómoda pausa que hizo visible lo invisible. Fue un momento que puso en evidencia la materialidad de la nube: lejos de ser una entidad abstracta, es un entramado físico de servidores, cables y centros de datos, sujeto a las mismas leyes de la física y a los mismos riesgos de error que cualquier otra obra humana.
La normalidad se ha estado restableciendo paulatinamente, con los equipos de AWS trabajando en «vías paralelas para acelerar la recuperación». Sin embargo, esto nos deja un mensaje para analizar en un mundo hiperconectado, donde el error en un servidor o en todo un centro de datos puede afectar nuestro día a día.
Relacionados